Experiments on APPS dataset¶
To test the performance of SFT training of OpenRLHF, we run experiments on the APPS dataset. We conduct SFT training on the APPS training dataset, and test the model on APPS test dataset. Below we list configurations of our experiment.
Dataset source: https://
Model: deepseek-coder-6.7b-instruct
Package version:
- openrlhf==0.5.3
- transformers==4.46.3
- ray==2.12.0
- flash-attn==2.7.0.post2
- deepspeed==0.15.0
- vllm==0.6.4.post1
- torch==2.5.1+cu121
- python 3.11.10
The full packages is provided here.
About package installation: The typical sequence is as follows: First, install torch. Next, download and install the appropriate version of flash-attn from the official releases page (installing flash-attn through pip directly might get stuck). It appears that the wheels should have cxxabiFALSE to function properly. Finally, install the remaining packages, for which running pip install openrlhf vllm should suffice.
Training procedure¶
I run the experiments on 8 A100-PCIE-40GB GPUs (r8a100-a) on r8nv-gpu-dist. I use 2 nodes (r8a100-a[02,03]) with 4 GPUs each. The main training script is as follows:
MODEL_PATH="/lustre/S/huangdi/open_for_out/models/deepseek-coder-6.7b-instruct"
OUTPUT_DIR="./checkpoint/dsc_6.7b_inst_sft_apps"
DATAFILE_PATHS="data/train_sft.jsonl"
HOSTFILE="${SLURM_SUBMIT_DIR}/hostfile"
deepspeed --hostfile $HOSTFILE --no_ssh --node_rank $SLURM_PROCID \
--master_addr $MASTER_ADDR --master_port=$MASTER_PORT \
--module openrlhf.cli.train_sft \
--pretrain $MODEL_PATH \
--dataset $DATAFILE_PATHS \
--save_path $OUTPUT_DIR/model \
--max_len 2048 \
--input_key question \
--output_key response \
--train_batch_size 256 \
--micro_train_batch_size 2 \
--max_epochs 2 \
--max_samples 5000000 \
--save_steps 16000 \
--logging_steps 1 \
--eval_steps -1 \
--zero_stage 3 \
--max_epochs 2 \
--seed 42\
--bf16 \
--flash_attn \
--learning_rate 2e-5 \
--packing_samples \
--use_tensorboard $OUTPUT_DIR/runs \
--apply_chat_template \
--gradient_checkpointing \During training, I encountered an error in multi-node training like the following form:
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
==================================================
finetune.py FAILED
--------------------------------------------------
Failures:
<NO_OTHER_FAILURES>
--------------------------------------------------
Root Cause (first observed failure):
[0]:
time : 2023-03-29_22:03:17
host : finetune-job-96q2q
rank : 4 (local_rank: 4)
exitcode : -7 (pid: 10)
error_file: <N/A>
traceback : Signal 7 (SIGBUS) received by PID 10
==================================================This is because the size of shared memory is not enough. Adding the following SBATCH options to the slurm file resolves the error:
#SBATCH --mem=0
#SBATCH --exclusivePlease note that compared to other frameworks, OpenRLHF consumes more GPU memory. To mitigate this, I use --gradient_checkpointing to reduce memory usage, though this might slightly impact the final model performance.
The training time for the two epochs are 5h07m54s and 5h07m30s respectively on the 8 GPUs from r8a100-a[02,03] respectively. It appears that training on r8nv-gpu-dist is faster than on r8nv-gpu-hw.
I also run an experiment without packing with the same GPU configuration, the total time cost for 2 epochs is 10h20m18s.
Training loss¶
Train loss with packing:
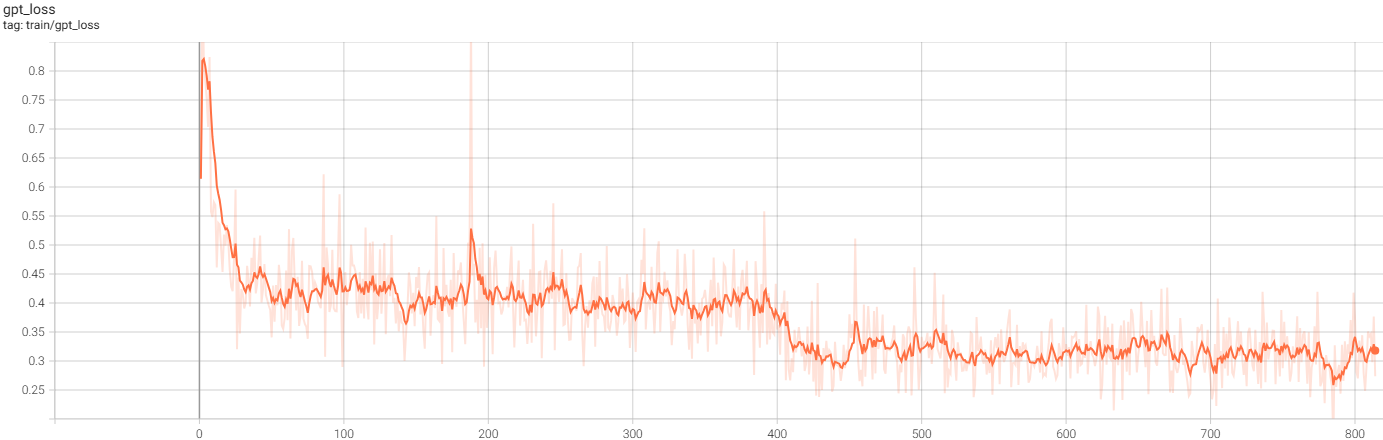
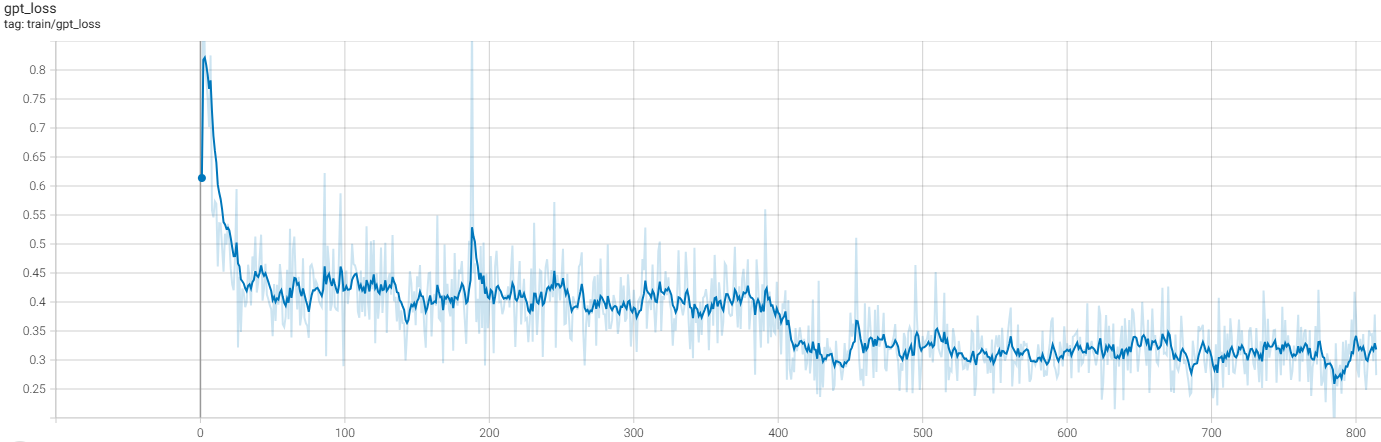
The training loss is illustrated in the figure above, with a noticeable decrease occurring around epoch 400. This decrease appears to be due to the model memorizing every sample during the first epoch and beginning to overfit in the second epoch. For further discussion, please visit this page on Zhihu.
A comparison of Train loss without packing:
Evaluation¶
Currently, a total of 3,765 problems from the test set are evaluated, with problems lacking solutions filtered out. For each problem, 10 pieces of code are generated. The sampling temperature is set to 0.6, and top_p is set to 0.95.
The inference stage is run on 4 GPUs from the node r8nv-gpu-hw-80g with the following command:
python -m llmkit_data.cli.sample --prompts $DATAFILE_PATH --out $SAMPLE_PATH --model $MODEL_PATH --gpu_per_model 4, and the evaluation stage is run on the node r8cpu with 32 CPU cores with the following command ($APPS_PATH is the folder containing train and test jsonl files, and remember not to put other data files in this folder):
python -m llmkit_data.cli.eval_apps --samples $SAMPLE_PATH --out $RESULT_PATH --apps $APPS_PATHInference is conducted using vllm, taking 30m43s for code generation, and approximately 39 minutes for evaluation.
For training with packing, the time cost for code generation is 42m01s and time for evaluation is around 39 minutes.
Results:¶
The pass@1, pass@5, and pass@10 statistics across different difficulty levels are presented in the table below:
| Difficulty | pass@1 | pass@5 | pass@10 |
|---|---|---|---|
| total | 0.12783532536520584 | 0.2306361854170619 | 0.2788844621513944 |
| introductory | 0.3449175824175824 | 0.5100187510901797 | 0.5604395604395604 |
| interview | 0.08309497616428309 | 0.17761538058567763 | 0.22845617895122847 |
| competition | 0.011612903225806452 | 0.04094982078853047 | 0.06129032258064516 |
A comparison of not adding packing:
| Difficulty | pass@1 | pass@5 | pass@10 |
|---|---|---|---|
| total | 0.1298273572377158 | 0.23352199666940704 | 0.2804780876494024 |
| introductory | 0.3458791208791208 | 0.5279685592185592 | 0.5934065934065934 |
| interview | 0.08533186651998534 | 0.17669571189923228 | 0.22185551888522184 |
| competition | 0.013870967741935483 | 0.041935483870967745 | 0.06129032258064516 |
For comparison, I also run an experiment for the original deepseek-coder-6.7b-instruct model. Its inference stage costs 47m50s and evaluation stage costs around 53 minutes. The inference is slower since it sometimes generates additional text, but the reason for slower evaluation stage is currently unknown. The pass@k statistics are shown in the following table:
| Difficulty | pass@1 | pass@5 | pass@10 |
|---|---|---|---|
| total | 0.11723771580345287 | 0.20706064630367418 | 0.24833997343957503 |
| introductory | 0.3244505494505494 | 0.46723465027036454 | 0.5260989010989011 |
| interview | 0.07418408507517418 | 0.1581393589094359 | 0.19801980198019803 |
| competition | 0.009354838709677418 | 0.026420890937019968 | 0.03870967741935484 |